Kubernetes Federation: The Basics and a 5-Step Tutorial
Learn about Kubernetes Federation use cases, how it works, and see how to create your first Kubernetes Federation in 5 steps.
What Is Kubernetes Federation?
Kubernetes Federation, or KubeFed, is a tool for coordinating the configuration of multiple clusters in Kubernetes. You can determine which clusters KubeFed will manage, and what their configuration looks like, all from a single group of APIs in the hosting cluster. KubeFed offers low-level mechanisms that can be used as a foundation for increasingly complex production Kubernetes use cases across multiple clusters, such as geographic redundancy and disaster recovery.
In this article:
Should You Use Kubernetes Federation?
KubeFed allows you to manage multi-cluster deployments more easily. It offers two main advantages for managing multiple Kubernetes clusters:
- Cross-cluster discovery—Federation can auto-configure load balancers and DNS servers with backends from each cluster. You can use this, for instance, to access the backends from various clusters through global VIP or DNS records.
- Resource syncing across clusters—Federation can keep the resources in various clusters synchronized. You can use this for example, for instance, maintain the same deployment across multiple clusters.
Additional use cases supported by Kubernetes Federation include:
- High Availability—Federation spreads the load across multiple clusters and auto configures load balancers and DNS servers, minimizing the impact of a cluster failure.
- No vendor lock-in—Federation allows you to migrate applications between clusters more easily, so you can avoid vendor lock-in.
Federation is only useful for multi-cluster deployments. Advantages of using multiple clusters include:
- Scalability—there is a limit to how much you can scale a single Kubernetes cluster.
- Reduced latency—you can minimize latency by deploying clusters in multiple regions, so that users are served from the clusters closest to them.
- Fault isolation—spreading your workloads over several smaller clusters, rather than one larger cluster, means that any fault that arises can be isolated.
Caveats
There are many good reasons to use Kubernetes Federation, but there are also several caveats:
- Higher network bandwidth and associated costs—the KubeFed control plane monitors all clusters to ensure they maintain the expected current state. If you are running your clusters in multiple regions or with different cloud providers, this can cause a significant increase in network costs.
- Limited cross-cluster isolation—if a bug reaches the control plane, it can affect all your clusters. You can mitigate this risk by reducing the logic in the control plane to the minimum required. KubeFed is also designed to err on the side of caution to maintain safety and prevent outages of multiple clusters.
- Lack of maturity—KubeFed is a recent development, so it doesn’t support all resources, while some resources still require Alpha clusters. There are still some issues with the project that the team is continuing to solve.
Alternative Solutions for Multi Cluster Kubernetes
Kubernetes Federation is not the only way to manage multiple clusters on Kubernetes. We’ll briefly review two more ways – the Cluster API, now a Kubernetes sub-project, and Google Anthos, a commercial offering by Google based on Kubernetes.
Cluster API
The Cluster API provides declarative APIs and tools that simplify the management of multiple Kubernetes clusters. The Cluster API can provision, upgrade, and operate multiple Kubernetes clusters from one control point.
Cluster API was initially developed by the Kubernetes Special Interest Group (SIG) Cluster Lifecycle. It is now a Kubernetes sub-project and it employs Kubernetes-style patterns and APIs to automate cluster lifecycle management.
When defining a cluster, the supporting infrastructure – including virtual machines (VMs), networks, load balancers, virtual private clouds (VPCs), and cluster configuration – are defined in the same style developers use to deploy and manage their workloads. This provides consistent as well as repeatable deployments of clusters across a wide range of environments.
You can modify the Cluster API to support all infrastructure types, including Amazon Web Services (AWS), Microsoft Azure, vSphere, bootstrap, or control plane providers.
Google Anthos
Google Anthos is a suite of products and services designed for hybrid cloud implementations and workloads running on Google Kubernetes Engine (GKE). Anthos lets you manage workloads that run on third-party cloud environments, such as AWS, Oracle, and Azure, as well as on-premises Kubernetes clusters.
The multi-cloud architecture of Anthos consists of several core software components, which run directly on Google Cloud. Anthos enables users to provision and manage GKE clusters on other cloud platforms, and also on-premises. These deployments are called managed clusters, because Anthos owns the entire lifecycle of all GKE clusters launched via its control plane.
Google Anthos provides tools that centralize the management of multiple deployment targets. It enables centralized configuration management across all environments. Anthos provides multi-cluster management through the GKE connection hub, Anthos Config for policy management and automation, and the Google Cloud console.
Kubernetes Federation Architecture
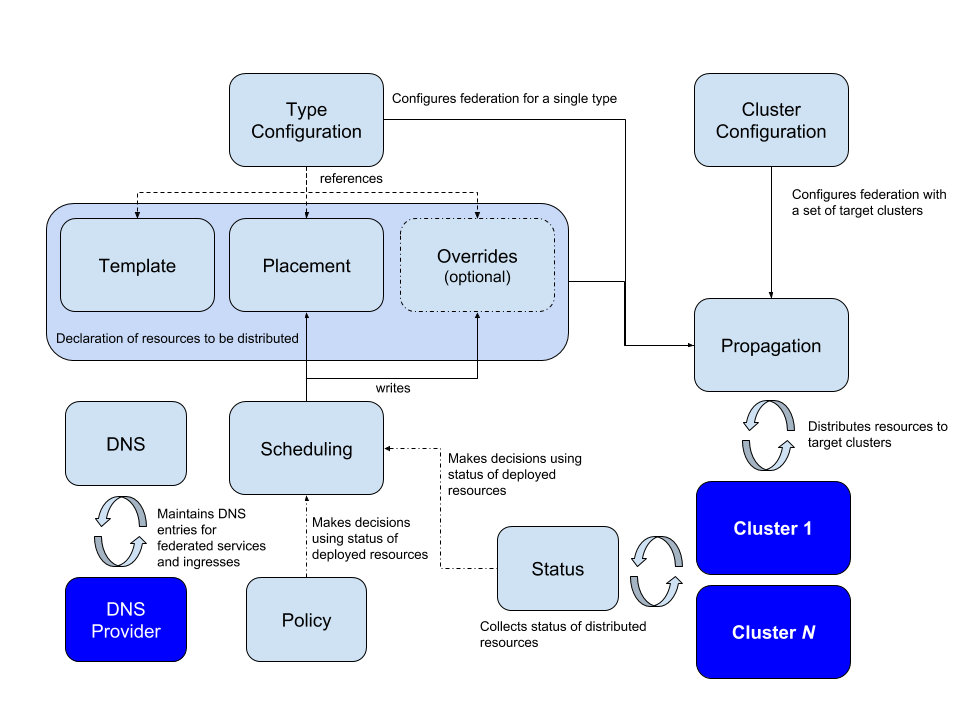
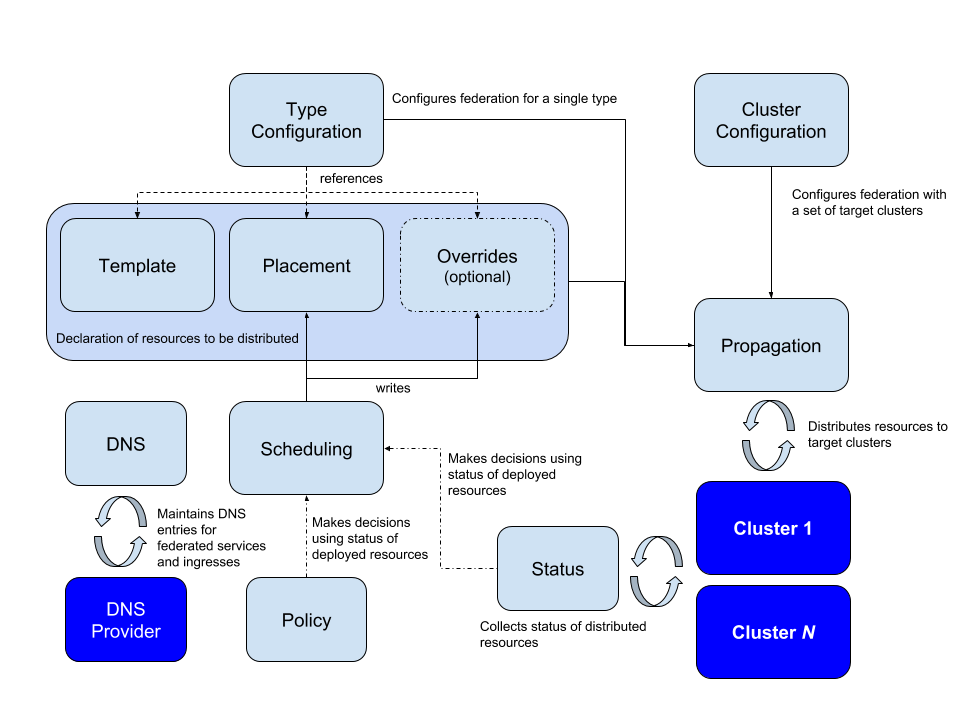
The central concept of Kubernetes Federation is a host cluster containing all the configurations to be propagated to the designated clusters. You can also assign real workloads to the host cluster, but it is generally easier to make it a standalone cluster.
All configurations throughout a cluster are managed through one API. A configuration determines which clusters it applies to and what they should do. A set of policies, templates and overrides specific to individual clusters determines the content of a federated configuration.
Federated configurations manage the DNS entries for all the multi-cluster services. A configuration must have access to any cluster it is intended to govern, in order to create configuration items and apply or remove them (this includes deployments). Deployments usually have their own namespaces, which remain consistent across clusters.
{kind=link}
KubeFed uses two kinds of configuration information:
- Type configuration—defines the types of APIs to be handled by KubeFed
- Cluster configuration—defines the clusters to be targeted by KubeFed
The mechanism for distributing a resource to member clusters of a federation configuration is called propagation.
There are three main concepts that inform type configuration:
- Templates—define how a common resource is represented across federated clusters
- Placement—designates the clusters intende to use the resource
- Overrides—define cluster-specific variations to the template at the field level
These three concepts represent resources intended for multiple clusters in a concise manner. They provide a minimum amount of information needed for propagation and can act as the link between propagation mechanisms and higher-order actions, such as dynamic scheduling and policy-based placement.
These concepts are the building blocks for higher-level APIs:
- Status—describes the status of a resource distributed across a federation of clusters
- Policy—defines the clusters to which a resources can be distributed
- Scheduling—determines how workloads are spread across various clusters (works similarly to a human operator)
Quick Tutorial: How to Set Up Federated Kubernetes Clusters
Step 1: Install Kube Federation on host cluster
Before starting to work with multiple clusters, first install the Kube Federation tool on the host cluster control plane, using the following command.
helm –namespace kube-federation-system upgrade -i kubefed kubefed-charts/kubefed –create-namespace –kube-context cluster1
Step 2: Join clusters into Federation
You will need the context for all the clusters that should join the federation. Run:
kubectl config get-contexts
Let’s say that you want to create a federation with two clusters, with the following contexts:
- Admin@cluster1
- Admin@cluster2
And you want Cluster1 to be the host.
You can now use the kubefedctl tool to join the clusters. Here is how to do this:
kubefedctl join cluster1 –cluster-context Admin@cluster1 –host-cluster-context Admin@Cluster1
kubefedctl join cluster2 –cluster-context Admin@cluster2 –host-cluster-context Admin@Cluster1
Step 3: Test that clusters have successfully joined
Make sure both clusters are available in the federation by running:
kubectl -n kube-federation-system get kubefedclusters
The output should look like this:
NAME READY AGE
cluster1 True 3m
cluster2 True 3m
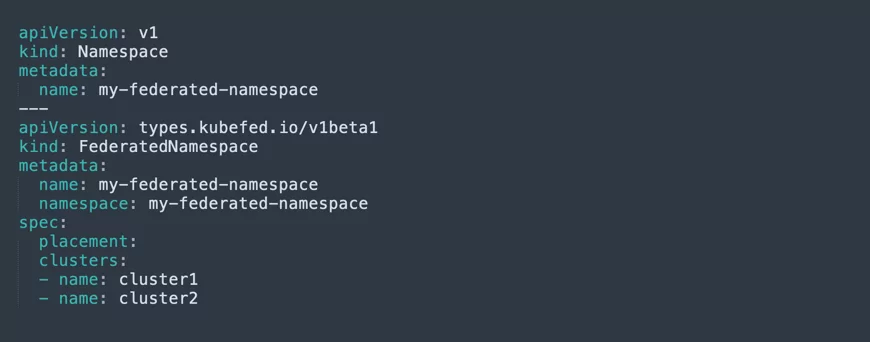
Step 4: Create a federated namespace
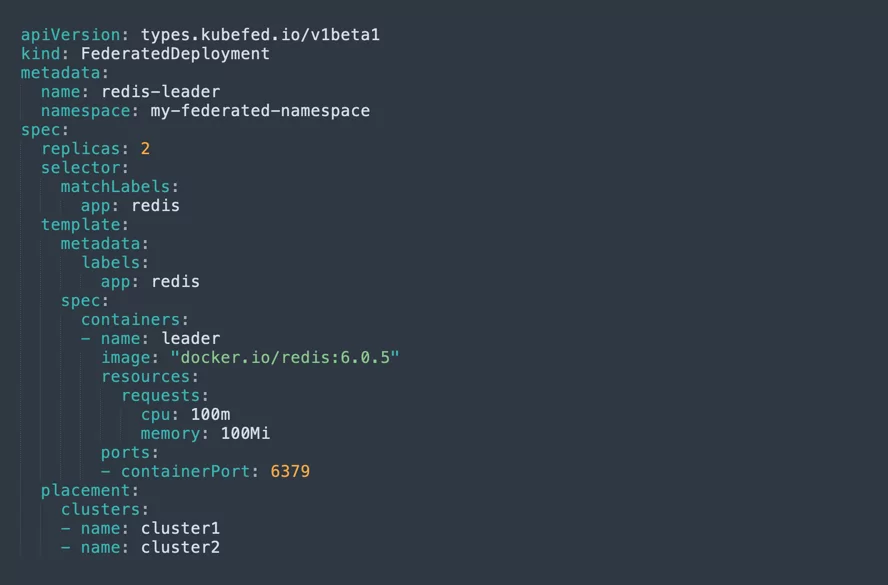
You can now create a federated namespace on the host cluster. This is very useful, because you can set Kubernetes resources to this namespace, and make them available to multiple clusters. To create a federated namespace, use a YAML configuration like this:
Step 5: Deploy an application to all clusters in the federation
This works similarly for Deployment or Service objects. We’ll show it for a Deployment. The following YAML configuration will let you deploy the Redis cache to the federated namespace—meaning it will be deployed automatically to both clusters in the federation.