
In recent years, I have been I using a project called BCC to compile, load, and interact with my bpf programs. I have recently learned about a better way to build ebpf projects called libbpf. There are a few good resources to use when developing libbpf based programs but getting started can still be quite overwhelming. The goal of this post is to provide a simple and effective explanation of what libbpf is and how to start using it.
libbpf is library that you can import in both your user space and bpf programs. It provides developers with an API for loading and interacting with bpf programs. It is maintained in the Linux kernel source tree which makes it a very promising package to rely on.
In order to illustrate the nature of libbpf and how to use it, I’m going to write a simple bpf program that tells us every time a process uses the mmap system call. Then I’m going to write a user space program, in C, which loads the compiled bpf program and listens for output from it.
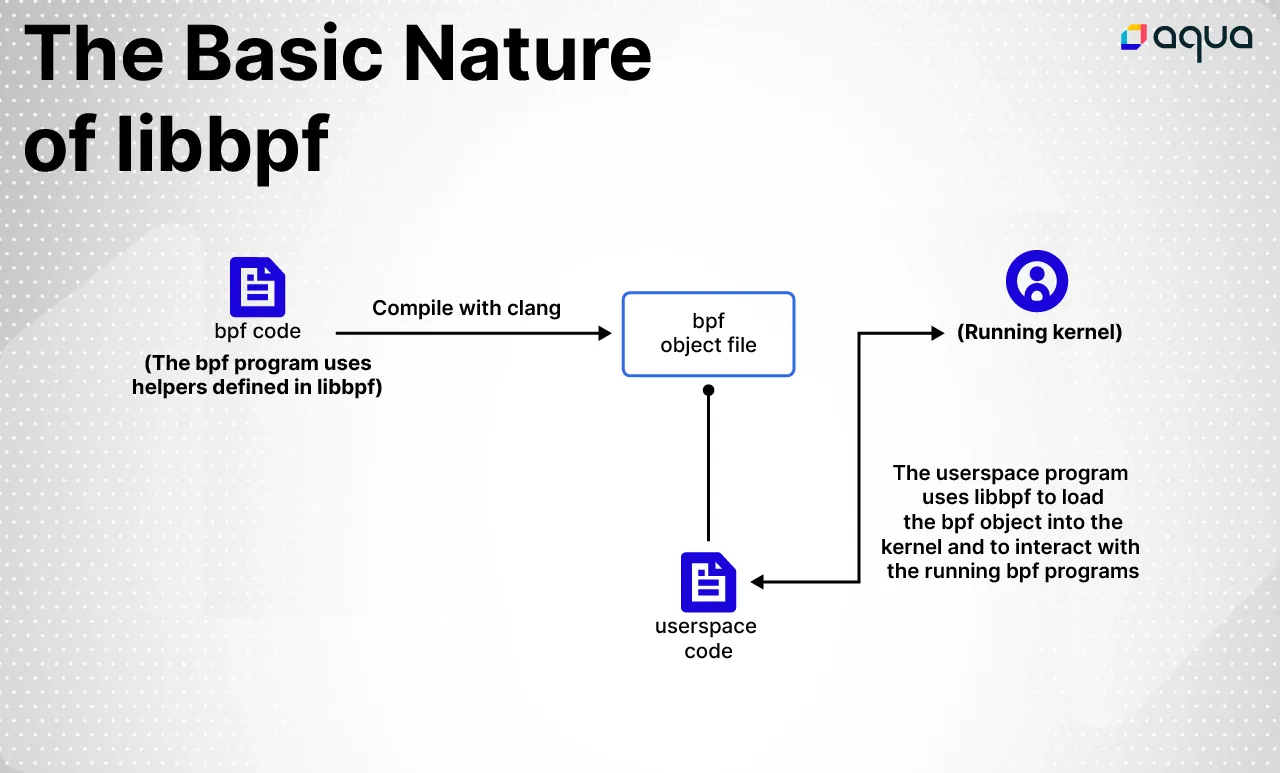
Writing a bpf program
Let’s start with the imports:
#include <bpf/bpf_helpers.h>
#include "vmlinux.h"
#include "simple.h"
The bpf_helpers.h header file is part of libbpf. As you might assume, it contains a lot of useful functions for you to use in your bpf programs. As for vmlinux.h, I wrote a complementary blog post on the subject you can check out: What is vmlinux.h and Why is It Important for Your eBPF Programs?
simple.h contains a struct definition that we want to include in bpf and user space code. That simply looks like:
struct process_info {
int pid;
char comm[100];
};
Now we’re going to need a way to transmit output to user space everytime the bpf program is called. For this we’re going to set up a ringbuffer:
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24);
} events SEC(".maps");
There are many types of bpf program maps you can use. Ringbuffers are a reliable way to transport data from kernel space to user space. If this isn’t the first bpf program you’ve written, you’ve likely also seen perfbuffers. In the blog post I linked above you can read about the benefits of using ringbuffers instead of perf.
Finally, let’s look at the actual bpf program:
SEC("kprobe/sys_execve")
int kprobe__sys_execve(struct pt_regs *ctx) {
__u64 id = bpf_get_current_pid_tgid();
__u32 tgid = id >> 32;
proc_info *process; // Reserve space on the ringbuffer for the sample process = bpf_ringbuf_reserve(&events, sizeof(proc_info), ringbuffer_flags);
if (!process) {
return 0;
}
process->pid = tgid;
bpf_get_current_comm(&process->comm, 100); bpf_ringbuf_submit(process, ringbuffer_flags);
return 0;
}
The bpf program itself is just this function, it’s essentially main(). We can define and import other functions of course, but those must be marked with the __always_inline attribute. This is to limit complexity and avoid any recursion as bpf programs must terminate!
So, let’s break this down.
SEC("kprobe/sys_mmap")
This is the section macro (defined in bpf_helpers.h). All programs must have one to tell libbpf what part of the compiled binary to place the program. This is essentially a qualified name for your program. There isn’t a strict rule for what it should be, but you should follow the conventions defined in libbpf. You can also see the SEC label above in the ringbuffer definition.
int kprobe__sys_mmap(struct pt_regs *ctx)
Here we can see that the program name is kprobe__sys_mmap. You can name it whatever you like and use this name as an identifier from the user space side. Every different type of bpf program has its own ‘context’ that you get access to for use in your bpf program. A good breakdown on the different things you can attach bpf programs to and what context is available for them can be found in this post on BPF program types.
In the case of this kprobe bpf program, we have a struct pt_regs which gives us access to the virtual registers of the calling process.
After this, it’s mostly self-explanatory:
proc_info *process
process = bpf_ringbuf_reserve(&events, sizeof(proc_info), ringbuffer_flags);
if (! process) {
return 0;
}
process->pid = tgid;
bpf_get_current_comm(&process->comm, 100); bpf_ringbuf_submit(process, ringbuffer_flags);
return 0;
We’re reserving space for a struct process_info on the ringbuffer, reading in the process ID, and the process name for it, and submitting it on the ringbuffer – that’s it!
Using libbpfgo user space side
Our goal for the user space program is to load the compiled bpf program, attach it to the appropriate kprobe, listen for the output from the ringbuffer, and clean things up when we’re done.
Since libbpf is a C library, it’s simple to create bindings for it in higher level languages, like Go. If you’d like to write your user space code in pure C, you can follow this post.
The first step is to compile the bpf code into an object file:
clang -g -O2 -c -target bpf -o mybpfobject.o mybpfcode.bpf.c
Now we can use libbpfgo, a thin wrapper around libbpf itself. The goal of libbpfgo is to implement all of the public API of libbpf so you can easily use it from Go. We’ve started with the features that tracee, one of Aqua’s open source projects, needs, but everything else will be coming soon!
Before we implement it in code, let’s look at a high level what we’re going to be doing:
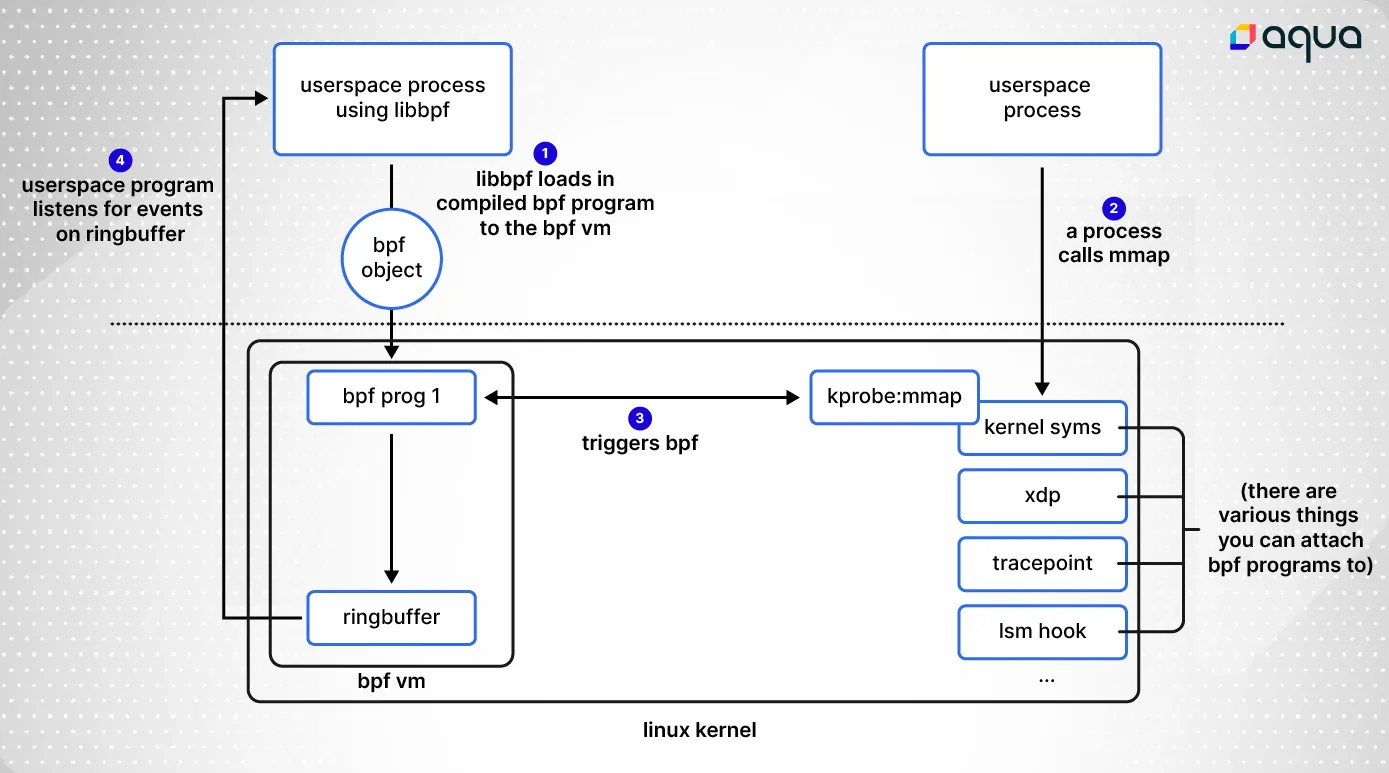
We can load in the object file like so:
bpfModule, err := bpf.NewModuleFromFile("mybpfobject.o")
if err != nil {
panic(err)
}
defer bpfModule.Close()
bpfModule.BPFLoadObject()
Next, we can find the bpf program that we want to use (you can put multiple into a single object file), and attach it to the hook we want to, in this case the __x64_sys_mmap kernel function.
prog, err := bpfModule.GetProgram(“kprobe__sys_mmap”)
if err != nil {
panic()
}
_, err = prog.AttachKprobe("__x64_sys_mmap")
if err != nil {
panic()
}
And finally, we set up a go channel to use for listening to output from the ringbuffer, and print out events as they come in.
eventsChannel := make(chan []byte)
rb, err := bpfModule.InitRingBuf("events", eventsChannel)
if err != nil {
panic()
}
rb.Start()
for {
eventBytes := <-eventsChannel
pid := int(binary.LittleEndian.Uint32(eventBytes[0:4])) // Treat first 4 bytes as LittleEndian Uint32
comm := string(bytes.TrimRight(eventBytes[4:], "x00")) // Remove excess 0's from comm, treat as string
fmt.Printf("%d %vn", pid, comm)
}
The only other thing to note is that we have to import “C” at the top of this file.
Building looks like this:
CC=gcc CGO_CFLAGS="-I /usr/include/bpf" CGO_LDFLAGS="/usr/lib64/libbpf.a" go build -o libbpfgo-prog
So we have a couple dependencies here that we need to have, but luckily they are provided by most package managers. /usr/include/bpf is the path to the libbpf source code on my system. If it’s not provided by your distribution (something like libbpf-dev) you can just commit the libbpf source code in your project repository. libbpf.a can either be built manually or provided by a package (something like libbpf-dev-static). The resulting binary will be named libbpfgo-prog.
Finally, you can either run this as root or with CAP_BPF/CAP_TRACING (linux 5.8+):
[*] sudo ./libbpfgo-prog
6400 sh
6399 sh
6401 node
6403 sh
6402 sh
6404 node
...
Wrapping up
In this post, I covered how to write a bpf program using helpers defined in libbpf. Our bpf program read information like the process ID and command then wrote it to a shared ringbuffer. We compiled it with clang, then used libbpfgo to load it into the kernel and listen for output from the ringbuffer.
Check out libbpfgo documentation, a good place to look for examples of usage would be in the libbpfgo tests. All of the code written for this blog post can be found on GitHub.
This post first appeared on Grant Seltzer’s blog.
