Blinders Off: Advanced Threat Detection in Cloud Native Runtime Environments
The second part of our cloud native security series focuses on detecting threats in the runtime environment, where attacks can cause the most damage if left unchecked. This session will explore advanced threat detection methodologies designed to minimize time to detection while protecting containerized and Kubernetes workloads without reducing performance.
Attendees will gain a clear understanding of the unique architecture of containerized applications and why securing the runtime layer requires specialized approaches. We will share the latest advancements, best practices for real-time monitoring, and techniques to identify early signs of compromise in cloud native environments. Learn how to tailor detection capabilities to your specific workloads and architectures to stay ahead of evolving threats.
This expert-led discussion will provide actionable strategies to strengthen your container security posture and safeguard your cloud native applications against sophisticated, real-time attacks.
Attendees will gain a clear understanding of the unique architecture of containerized applications and why securing the runtime layer requires specialized approaches. We will share the latest advancements, best practices for real-time monitoring, and techniques to identify early signs of compromise in cloud native environments. Learn how to tailor detection capabilities to your specific workloads and architectures to stay ahead of evolving threats.
This expert-led discussion will provide actionable strategies to strengthen your container security posture and safeguard your cloud native applications against sophisticated, real-time attacks.
Transcript
Hello, everyone, and welcome to the second session of our run time security series.
My name is Joe Murphy. And we're thrilled to have you.
Before we dive in, last week, we laid the groundwork for understanding runtime security and cloud native. Discussed the importance of continuous security measures and took a deep dive into the current threat landscape, focusing a lot on complexities and the unique challenges that it poses in cloud native environments.
So building on that foundation, today's agenda includes a quick recap of the threat landscaping cloud native. We're gonna have a breakdown of the anatomy of cloud native attacks. We're gonna share some very, very interesting data from the real world, and we'll wrap up with the approaches and tech for cloud native security.
So a reminder, everyone, this session is being recorded. A copy of the recording in the slides will be shared via email. Shortly after the presentation.
And we encourage everybody to, engage in the conversation, ask questions, and comments throughout the session, feel free to use the chat or the Q and A feature. In fact, feel free to, to let us know where you're joining from today via the chat and get that going. And, we'll save some time at the end to answer any questions that might come up. So without further ado, let's get started. I'd like to introduce your speaker, Tsvi Korren, Aqua Security field CTO, Tsvi? Take it away.
Alright. Thank you, Joe. Thanks everybody for, for joining.
If you've been to the last session, that we presented last week, you might have seen this slide. Which is really kind of our story so far. And our story so far is around the growth of, the attack but also the attacks themselves and some of the things that we're seeing, as it relates to cloud native technologies and how attackers are using cloud native technologies to further their cause. And we've seen, you know, the attack volume rise.
We've seen the fact that, there is an emphasis on bypassing agentless controls going straight to the workload. We've seen that there are a lot of backdoors left in attacks seen that there is worms deploys, in attacks and really the fact that, attackers can really find you. Right? There's really no way to hide because everything is in the open and there are, ways to, borrow from the internet into the the insides of, of workloads.
If you haven't seen that session and you wanna get more information on, on how those attacks happen and and some of the, attacks that we find through our research, you can go and listen to the recording, and it will be available, adjacent to the link that you're gonna get today. So this has been our our story so far. And the reason is is the question is why why are these attacks really happening? Why is the increase in the attacks happening? And there's two things that that come out of the data that we presented in the last session. One is that there is an increase in the attack surface There's an increase in the, complexity of cloud native deployments.
There is increasing the vulnerabilities, a lot of use of open source, And there's a lot of opportunities for attackers to go after those cloud native environments.
Another thing that happens is that the methods that attackers are using are becoming more and more sophisticated. It's not just, you know, going and and, you know, exploiting accountability and and and using it in one workload, it's these are multistage of taxes or takes to take advantage of in memory attacks covering their tracks and all the things that and make it very, very hard to defend against. So when we look at what this successful attack actually looks like, we need to take a look at what are the components that didn't bring about the ability to execute those attacks. And if we talk about the the attack surface the risk is increasing and also the methods.
These are really the two things that will constitute a successful attack. Now the risk that we talk about can be, you know, vulnerabilities in open source. It can be misconfigurations in cloud environments. It can be just mistakes in coding.
It could be going after the software supply chain and the ability of attackers to, in search code even in open source repos. And these are all the the risks that that we need to deal with as we look at what the threat landscape is.
Not every risk is exploitable, not every risk is also Right? So while while there are certain risks that we know of that can be harnessed to for attacks, there are also a lot of risks that are superfluous that that will not lead to an attack. And there's also a lot of risk that we really don't know about. So all these unknown flows on all these unknown vulnerabilities they are still still being discovered every day, also contributes to to to the risk landscape.
On the other side, the threat landscape are all the methods that attackers are used to get into our workload. So that could be, straight on remote code executions, could be malware, could be in memory attacks, could be attacks against the the infrastructure in cloud native. The infrastructure is a lot bigger, so it could be attacks against Kubernetes attacks against cloud environments. And it can also be, all these, what we call suspicious activities, right?
The the fact that, some, you know, a network has spiked or that a a process that we didn't expect, popped up in a workload. Again, doesn't mean that this is the real threat that constitutes attack, but these are all the things that we need to deal with. If we're going to find that cross section between threat and risk that makes it possible for people to attack our our environments. And as defenders, there's a few things that that we can do.
Now if we're gonna do that, we need to think like an attacker. So what what would attacker want to do? Attackers usually want to exploit your risk. They wanna get into, a situation where there is something that they can used to start their work, inside of our environment.
If they find it, they will execute a threat. They will execute the methods that would enable them to further their cause inside of our environment. And from then on, there are multiple things that you can do. You can, expand your foothold.
You can propagate to other servers. But at end of the day, what they really want is, you know, either disrupting the service just just for fun or for for other purposes. A lot of times it's adding back doors that would just sit there for a while waiting to be exploited.
Once somebody owns their workload, they can really do anything, steal information, you know, run miners, and and exploit the infrastructure for for their for their purposes.
There are a lot of avenues that that that can manifest itself in this kind of environment. If we overlay really what we know as the risks and the threats that that we've identified, We can see that just by looking at misconfigurations, vulnerabilities, insecure coding, and supply chain, these are three avenues that attackers can choose in order to go to the Once they execute a threat, they can propagate to straight on to the server, elevate their privilege and own the workload, but they can also go around it. Right? They can, try to make use of the container engine.
If we're talking about cloud native applications, they can connect to Kubernetes, they can launched her own workloads. So the paths of attacks are becoming more and more sophisticated. This is not just a straight on line between attacker and a server. This could be very, sophisticated, and they can, provide a they they can cause a really problem in our ability to track them and really understand what is a component of an attack and what is something that may be a lower level risk.
So If if we are as as defenders as people who who want to understand and, and counter those, those avenues for tax, There's a few things we can do. If we talk about the the risk side, you know, misconfigurations vulnerabilities and and insecure code, the answer to that has always been risk a risk scanning. Right? We need to identify the risks, understand what are the known risks that we have in the environment.
Not everything can be fixed, not everything can at the same time. We're in a timely fashion because as you as you will see, the numbers are really growing. So we need to prioritize that risk. Once that risk is prioritized, we actually need to go in fix it.
And that depends if there is a fixed version, let's say, for availability, or we can, in a timely fashion, close that hole in the misconfiguration of the cloud. And then we need to measure that we fix it. Really validates that this risk no longer happens. And we do it again and again and again in, you know, me everybody on on this on this webinar has has done some kind of weakness or vulnerability analysis and have started the process closing out those vulnerabilities and and removing the risk.
What we're seeing in in the real world is that when we scan and this is numbers that are coming from Aqueous cloud platform in in aggregate.
On average, what we're seeing that, you know, the average typical, environment that Aque was protecting as close to a hundred and seventy thousand vulnerabilities in container images. You know, you may have less, you may have more depending on, of course, how many images you have and what is your technology stat, But on average, we're talking about a, you know, a hundred and seventy thousand vulnerabilities.
We're also talking about tens of thousands of cloud misconfigurations and and also in that vicinity of cloud cloud repo security findings, meaning that there are actually weaknesses in the configuration of our dev ops tools or there are things that could, expose us to to, attacks on the the supply chain and everything that happens before we deploy an application. So if you think about those numbers, a hundred and seventy thousand vulnerabilities, this is not something that you can actually fix in one day or maybe even ever. Right? So we need to prioritize them. Same with cloud misconfiguration.
What are the cloud holes that we need to to block? And those are dependent on the nature of the application. And of course, what is the nature of of the risk. And so on.
So those numbers, are really big and it becomes, increasingly impossible to really understand what is our posture for for security just because of of the volume. So let's say that we've even blocked some of the risk on that that maybe an attacker was able to to exploit some of the risk and they go on to executing their right. Going to, you know, maybe doing a remote code execution or maybe the ability to to exfiltrate data, maybe connecting to Kubernetes. And here, it's a it's a similar structure.
It happens more in real time. These are not static scans that happen once in a while. This has to be done in real time. We need to have visibility into everything that's running in our workflow.
We need to have really good detection understanding what are the patterns, what are the behaviors that we're seeing that associated with threats. And then we have to take a decision. Are we going to block the threat? Are we going to just live with it?
Are we going to just let it play on? Is it really something that we that is important? Is it something that we need to generate a response? And then when we generate a response, what should that response be?
Are we gonna shut down the workload? Are we going to, maybe just counter that particular action by an attacker So again, a lot of decision making that needs to take place and unlike with scanning where we have a little bit of time usually to to to, defend the risk those decisions and the responses really have to happen fast because if a and and and tech is underway and people are starting to siphon data off of your environment, we need to shut that down as soon as possible. Right? We can't wait, you know, a week or two like like we would maybe fixing a vulnerability.
So A little bit more data, right, Apple is also providing that active protection to to our customers. And we are monitoring, a lot of workloads in the in the environment. So we are seeing on average, again, from our data, about a hundred and thirty six types of threat activity. So that would be the method attackers are using. So a hundred and thirty six unique methods that we've seen that attackers are using to, either probe the environment or gain a foothold in the environment or execute the threats in the environment. We are seeing, and this is the data that is about, a month old.
During the course of a month, these are not, you know, real time running, workloads, but over the course of a month because workloads come and go, there is an aggregate, thirty five thousand four hundred workloads with threat activity per month. So so think about it. Right? They are at least those amounts of of of workloads that could be affected by an attack, and we need to sort and make the decision really quickly on whether or not we want to respond to an This is even worse because we have, you know, hundreds of thousands of threat activities per day. Right? So On average, if you think about it, there are about, you know, four, five, six threat activities per day per workload.
And that means that we are starting to see a lot of inflow into our security information management systems and to the decision making of whether or not we want to to identify the thread. And those require us to really be vigilant. Right? We need to understand exactly what's going on in the container what's going on in a function and exactly what's going on in your VM and and understand whether or not this is part of a threat, part of an attack and make that that that that respond as as quick as possible.
And to be honest, it's just a lot to deal with. Security organizations, are not really built to do this the way that we used to do it with, servers. Right? Because the amount of workloads is increasing the amount of complexity, putting workloads in a cloud environment is is complex, and everything that we talked about in the previous session. Again, if you haven't heard that, go go and listen to it and we'll describe the the, that complexity and why the volume of both findings and attacks have been have been increasing.
So it's a lot to deal with. Now it doesn't mean that we just need to give up. It just means that we need to work a little bit smarter. But before we work smarter, let's let's just describe how we work today in general on both sides.
Right? The scanning for risks and and and doing threat detection in real time. Well, right now, for the most part, even in cloud native, this is still a siloed process. These are still two distinct processes that happen in environments.
On the one side, we scan for risk and, you know, identify them prioritize and fix them to the best of our ability. And we're using objective measures. Right? In order to understand if the risk should be prioritized, we are using things like, the scores like, the severity of the, of the vulnerability or the the the misconfiguration, we are able to, then based on those objective measures, prioritize how we want to, fix those and then, you know, measure that we indeed fixed them.
Now we're not gonna fix everything just because of the volume. But those objective measures are thought to be enough to actually prioritize, our threats. A similar thing is happening in runtime. Runtime doesn't have as much as methodology of scoring that it has on the on the risk side, but there are some frameworks like the minor attack framework that that if you can map our detections of what is going on behaviorally inside of an application, we can actually understand, you know, what decision we need to take because we know what phase of the attack this is associated with and and whether or not we have a, an attack in in place once we see an aggregate of those of those threats.
And again, this is a completely different, different function, and sometimes it's handled in a different part of the the organization.
It means that, the people that scan for risks and scan for, let's say, cloud misconfigurations are doing their and in parallel, other people probably the security operation center, probably with the help of security information management, are looking at those threats and determining whether or not they need to generate a response.
This is a problem. It's a problem because those two organizations are still drowning in a lot of findings.
And and the fact is that sometimes we find ourselves covering and prioritizing risks that maybe would not lead to a threat being exploited, right, because the that Venn diagram between risk and threat is not a hundred percent match. On the other hand, we could find ourselves chasing a lot of threats that look like they can be exploited, but because of the structure of the infrastructure and because of of, maybe some compensating measures, really attackers won't be able to execute their attacks. So there's a lot of time and effort wasted in both these silos and things that are not relevant.
And again, because we're drowning in a lot of data, it could be the one that we are missing. It could be the one that we are not prioritizing, and then the attack, might have So we really need a better way. And this is where we start to to put these two things together. If we could have a synergy between what we do with scans and what we do with runtime.
If we can feed data from one to the other, we should be able to have a better outcome actually on both sides.
So if we take everything that we know about the risk ins and the result of the risk ins, so we know what risks are in the wild, and it's not just the objective measure of the vulnerability severity and score. It's also whether or not there is active vulnerabilities exploit that happens in the wild. Do we have an exploit published, which makes it a lower barrier to entry for attacks to exploit it? That should actually hone what we do at runtime and we can, have better decision making as we do the response.
Same thing with the component source. Right? If we're seeing components that are being active at runtime, but their source is questionable whether or not they're coming from the external externally to the organization or they have, maybe the repos are not well maintained and there is a chance that, there may be some repo pois poisoning Again, we can hone our policies, we can hone our response on the threat side. And another very important thing that comes with scans is really the expected behavior because it's not just the objective measure of what the risk is and, whether or not we have vulnerabilities or misconfigurations, it also speaks to what the components of the application and what we we expect the applications to do.
Right? We have the ability to see, let's say, in Docker files, the the entry point of the of the the container in Kubernetes files. We have the expected, ports that are going to be used in what's being exposed. So so we can actually start to see what the expected behavior again, which will help us hone our decision response at runtime.
Sending actually happens the other way around.
What we're able to do is to take the data that we have at run time and reflect on what we actually need scan or better yet what we need to prioritize in order to fix the threat. Right? So if we have, you know, a hundred thousand vulnerabilities in, let's say, across thirty thousand resources, But we know from our runtime detection that really only, you know, five thousand, six thousand upload resources are are in use, that those are the ones that we need to prioritize on the scan because those are the ones that any intrusion is going to happen. Right?
Intusion is not going to happen on a code that's not running. Same thing happens with the existing mitigation. There is a vulnerability that could cause a remote code execution. It's dependent on a porch being open or it's dependent on the ability of the user to gain shell access.
And we block those two things. You know, we don't allow shell access or we don't allow, traffic on a particular port, then again, maybe we need to deprioritize that. On the other hand, if there are vulnerabilities that we are seeing that we that we know that we don't any existing mitigation at runtime.
Then first of all, we can put up that that that mitigation at runtime if we can, but also those are the ones that we need to prioritize.
In order to fix. And of course, they're just the general observed behavior. Right? We need to statistically understand, what where the threats first steps are coming from, whether the things that, attack as we're trying to exploit and not in a general sense, that's not the temporal score of what's out there in the wild.
This is actually what's happening in each and every environment so that you can have better understanding of the risks that are being exploited. And again, we can prioritize them, to make that a much more ironclad environment so that we don't have that risk to begin with. That attackers will not be able to to exploit it. So all of these things are leading us to needing a lot of data.
And what are the things if you've seen our last session is that Akwa's research arm, we we call team Nautilus are the ones that are responsible to provide us with the data both objectively and eventually leading to the data based on our environment as to what the risks are and what the threats are. Now we have components that sit all the way in the development environment in the code repos, in the CICD, we can scan images from the registry, scan artifacts as they are running and provide the that runtime detection.
At, for threats that happening when, when workloads are actually up. So all of that is, a result all the recent. I'll I'll give you two examples. Right? If if we are talking about just the risk and let's take vulnerabilities for instance, we all know that vulnerabilities have a severity and they have a score.
And there are multiple ways to do that scoring, you know, the c b s s one and c b s two and c b s three. And we are now finding ourselves in a way that we need to classify that that that vulnerability. Well, it's not just two or three or four data points. They are actually, you know, dozens of data points that we can look at at a particular vulnerability it could be, you know, where the vulnerability is coming from, what image in your environment is it coming from?
What is the severity of that unability. What is the authoritative score? It could come from the NVD as an objective score, or it could come from the maintainer of the package. If it's an open source package, and sometimes they disagree, and we need to understand that if we are going to prioritize that correctly.
We need to understand if there is a an exploit code exists. If right now, things are being exported in the world. We need to understand, you know, where are the containers that are running, what the workloads they are running, what resources are there, how to fix them, how to fix them in a way that, might just update that component, or do we need to update the entire, let's say, base operating system? So these are all data points that we can use in order to make a decision on whether or not we want to prioritize a particular vulnerability in our environment.
Now, you know, multiply that by hundreds of thousands, and and we do get, a lot of, a lot of data, but it's data that actually is not hurting us. It's not an overwhelming amount of data. It's just data that helps us prioritize and and aquaize an automated system can can really help you prioritize based on all the the data points.
Another thing is on the risk side, on the, on the threat side. Right? What's happening on the threat side is, again, a lot of behaviors that are taking place inside of our, workloads. Some of them are benign. Some of them are are more dangerous than others. Some of them are only dangerous in combination.
So we have over a hundred types of threat activity. Right. Remember, we are finding a hundred and thirty six on average.
Individual, threat patterns that we identify in in our customers. We are mapping those to the minor categories so you can get some objective measures about what's going on in the environment. But then we also want to reflect specifically on cloud native. You know, are we going against Kubernetes?
Are we going against the container engine. Are we trying to, preempt what was in the image and insert more executables into a container. So this is this is the list of of, typical actions that would happen in real time. And we are we are also sorting them and we're able to to provide, that analysis, of an individual action that happens whether or not it is in a process of an active attack, or is it just something that is detached and just happened once?
And of course, in cloud native, because everything is replicated, we can also reflect on whether or not it happens in a lot of workloads or in some workloads and and there's no, you know, good good or bad of whether or not an attack is less important because it happens in work with one workflow or multiple workloads. We just need to take it as a data point and add that to the decision of the of the response. So by taking all these data points together and and all the different workload types that we have in cloud native, what we are able to do is to, have a continuous assessment, of risk leading into an assessment threat.
So, you know, on the risk side, we can, you know, scan our VMs to understand if there are misconfigurations or or vulnerabilities. We can do that, of course, with the cloud.
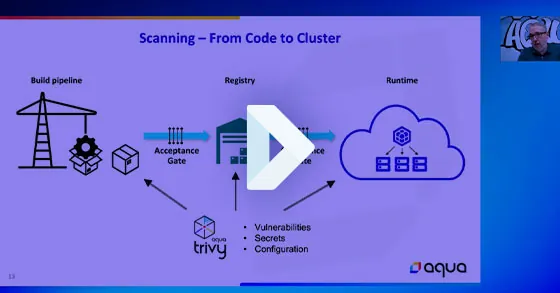
We can, scan containers, based on the images that they have, come from. We can take a look at the Kubernetes resources, take a look at the Kubernetes configuration files a lot of times we wanna put an acceptance gate so that if we are seeing a workload that is gonna come with something that is a risk. We might want to deny that risk and prevent that risk from going into runtime.
In containerizations specifically because we are always dependent on the image. We have the ability to identify drift between a running container and its image. That's usually an indication that something is going wrong, not an indication necessarily of an active attack, but a very strong data point, that we we can plus it's it's always a good idea to stop changes to running, cloud native workloads because they're supposed to be immutable. And then we have, the ability to put some runtime policies in place that would harden it rushing to lock attack in in action, and provide you with, with at least a little bit of time to understand what goes on so that you are able to fixed fixed the risk or or have more of an elaborate incident response.
Of course malware is part of it and just general threat detection pattern based to to understand what goes on. Now the middle part there, you know, where it says cloud native only, these are really specific to cloud native, but we don't have the ability to you know, do containers if we're just running in VMs. We also don't have Kubernetes if we're if we're just running in traditional VMs. But we also don't have this acceptance Right? Because VMs are built over time and are not just triggered from a prefab image. So all these qualities of what cloud native is, and again, for to our previous session, are are going to both, you know, increase the complexity of of what we need to defend, but also gives us a little bit of help because it provides us with a baseline on which we can we can base our our responses.
So when all of this is put together, the ideal is that if we identify an attack and if we can correlate that to a risk that is already known, we will have much more confidence on how we can stop that attack. And this is where we are, gonna show you in our next session, that is gonna be next week around how can we affect an effective response without downtime in those cloud native applications? Well, how can we, detect that risk make sure that at risk is appropriate for our environment.
And then if we see a threat that tries to exploit that risk, how can we stop it without taking down the application with us. There's a lot of interesting things that Apple is doing at runtime in order to prevent those cloud native attacks from from, coming on, but also stop them, when they're there. So, I hope you'll join our next session when we discuss how we can actually bring all this together. And stop cloud native attacks without impacting the application.
Thank you so much.
See, folks, I put a link into, into the chat. Lot of reference of last week's session. For those who didn't make it, there's a link to the recording right in the chat. You can, check that out, at your leisure, and then also a link to the registration page for next week.
So, Tsvi, thank you so much. That was a lot of great information.
My name is Joe Murphy. And we're thrilled to have you.
Before we dive in, last week, we laid the groundwork for understanding runtime security and cloud native. Discussed the importance of continuous security measures and took a deep dive into the current threat landscape, focusing a lot on complexities and the unique challenges that it poses in cloud native environments.
So building on that foundation, today's agenda includes a quick recap of the threat landscaping cloud native. We're gonna have a breakdown of the anatomy of cloud native attacks. We're gonna share some very, very interesting data from the real world, and we'll wrap up with the approaches and tech for cloud native security.
So a reminder, everyone, this session is being recorded. A copy of the recording in the slides will be shared via email. Shortly after the presentation.
And we encourage everybody to, engage in the conversation, ask questions, and comments throughout the session, feel free to use the chat or the Q and A feature. In fact, feel free to, to let us know where you're joining from today via the chat and get that going. And, we'll save some time at the end to answer any questions that might come up. So without further ado, let's get started. I'd like to introduce your speaker, Tsvi Korren, Aqua Security field CTO, Tsvi? Take it away.
Alright. Thank you, Joe. Thanks everybody for, for joining.
If you've been to the last session, that we presented last week, you might have seen this slide. Which is really kind of our story so far. And our story so far is around the growth of, the attack but also the attacks themselves and some of the things that we're seeing, as it relates to cloud native technologies and how attackers are using cloud native technologies to further their cause. And we've seen, you know, the attack volume rise.
We've seen the fact that, there is an emphasis on bypassing agentless controls going straight to the workload. We've seen that there are a lot of backdoors left in attacks seen that there is worms deploys, in attacks and really the fact that, attackers can really find you. Right? There's really no way to hide because everything is in the open and there are, ways to, borrow from the internet into the the insides of, of workloads.
If you haven't seen that session and you wanna get more information on, on how those attacks happen and and some of the, attacks that we find through our research, you can go and listen to the recording, and it will be available, adjacent to the link that you're gonna get today. So this has been our our story so far. And the reason is is the question is why why are these attacks really happening? Why is the increase in the attacks happening? And there's two things that that come out of the data that we presented in the last session. One is that there is an increase in the attack surface There's an increase in the, complexity of cloud native deployments.
There is increasing the vulnerabilities, a lot of use of open source, And there's a lot of opportunities for attackers to go after those cloud native environments.
Another thing that happens is that the methods that attackers are using are becoming more and more sophisticated. It's not just, you know, going and and, you know, exploiting accountability and and and using it in one workload, it's these are multistage of taxes or takes to take advantage of in memory attacks covering their tracks and all the things that and make it very, very hard to defend against. So when we look at what this successful attack actually looks like, we need to take a look at what are the components that didn't bring about the ability to execute those attacks. And if we talk about the the attack surface the risk is increasing and also the methods.
These are really the two things that will constitute a successful attack. Now the risk that we talk about can be, you know, vulnerabilities in open source. It can be misconfigurations in cloud environments. It can be just mistakes in coding.
It could be going after the software supply chain and the ability of attackers to, in search code even in open source repos. And these are all the the risks that that we need to deal with as we look at what the threat landscape is.
Not every risk is exploitable, not every risk is also Right? So while while there are certain risks that we know of that can be harnessed to for attacks, there are also a lot of risks that are superfluous that that will not lead to an attack. And there's also a lot of risk that we really don't know about. So all these unknown flows on all these unknown vulnerabilities they are still still being discovered every day, also contributes to to to the risk landscape.
On the other side, the threat landscape are all the methods that attackers are used to get into our workload. So that could be, straight on remote code executions, could be malware, could be in memory attacks, could be attacks against the the infrastructure in cloud native. The infrastructure is a lot bigger, so it could be attacks against Kubernetes attacks against cloud environments. And it can also be, all these, what we call suspicious activities, right?
The the fact that, some, you know, a network has spiked or that a a process that we didn't expect, popped up in a workload. Again, doesn't mean that this is the real threat that constitutes attack, but these are all the things that we need to deal with. If we're going to find that cross section between threat and risk that makes it possible for people to attack our our environments. And as defenders, there's a few things that that we can do.
Now if we're gonna do that, we need to think like an attacker. So what what would attacker want to do? Attackers usually want to exploit your risk. They wanna get into, a situation where there is something that they can used to start their work, inside of our environment.
If they find it, they will execute a threat. They will execute the methods that would enable them to further their cause inside of our environment. And from then on, there are multiple things that you can do. You can, expand your foothold.
You can propagate to other servers. But at end of the day, what they really want is, you know, either disrupting the service just just for fun or for for other purposes. A lot of times it's adding back doors that would just sit there for a while waiting to be exploited.
Once somebody owns their workload, they can really do anything, steal information, you know, run miners, and and exploit the infrastructure for for their for their purposes.
There are a lot of avenues that that that can manifest itself in this kind of environment. If we overlay really what we know as the risks and the threats that that we've identified, We can see that just by looking at misconfigurations, vulnerabilities, insecure coding, and supply chain, these are three avenues that attackers can choose in order to go to the Once they execute a threat, they can propagate to straight on to the server, elevate their privilege and own the workload, but they can also go around it. Right? They can, try to make use of the container engine.
If we're talking about cloud native applications, they can connect to Kubernetes, they can launched her own workloads. So the paths of attacks are becoming more and more sophisticated. This is not just a straight on line between attacker and a server. This could be very, sophisticated, and they can, provide a they they can cause a really problem in our ability to track them and really understand what is a component of an attack and what is something that may be a lower level risk.
So If if we are as as defenders as people who who want to understand and, and counter those, those avenues for tax, There's a few things we can do. If we talk about the the risk side, you know, misconfigurations vulnerabilities and and insecure code, the answer to that has always been risk a risk scanning. Right? We need to identify the risks, understand what are the known risks that we have in the environment.
Not everything can be fixed, not everything can at the same time. We're in a timely fashion because as you as you will see, the numbers are really growing. So we need to prioritize that risk. Once that risk is prioritized, we actually need to go in fix it.
And that depends if there is a fixed version, let's say, for availability, or we can, in a timely fashion, close that hole in the misconfiguration of the cloud. And then we need to measure that we fix it. Really validates that this risk no longer happens. And we do it again and again and again in, you know, me everybody on on this on this webinar has has done some kind of weakness or vulnerability analysis and have started the process closing out those vulnerabilities and and removing the risk.
What we're seeing in in the real world is that when we scan and this is numbers that are coming from Aqueous cloud platform in in aggregate.
On average, what we're seeing that, you know, the average typical, environment that Aque was protecting as close to a hundred and seventy thousand vulnerabilities in container images. You know, you may have less, you may have more depending on, of course, how many images you have and what is your technology stat, But on average, we're talking about a, you know, a hundred and seventy thousand vulnerabilities.
We're also talking about tens of thousands of cloud misconfigurations and and also in that vicinity of cloud cloud repo security findings, meaning that there are actually weaknesses in the configuration of our dev ops tools or there are things that could, expose us to to, attacks on the the supply chain and everything that happens before we deploy an application. So if you think about those numbers, a hundred and seventy thousand vulnerabilities, this is not something that you can actually fix in one day or maybe even ever. Right? So we need to prioritize them. Same with cloud misconfiguration.
What are the cloud holes that we need to to block? And those are dependent on the nature of the application. And of course, what is the nature of of the risk. And so on.
So those numbers, are really big and it becomes, increasingly impossible to really understand what is our posture for for security just because of of the volume. So let's say that we've even blocked some of the risk on that that maybe an attacker was able to to exploit some of the risk and they go on to executing their right. Going to, you know, maybe doing a remote code execution or maybe the ability to to exfiltrate data, maybe connecting to Kubernetes. And here, it's a it's a similar structure.
It happens more in real time. These are not static scans that happen once in a while. This has to be done in real time. We need to have visibility into everything that's running in our workflow.
We need to have really good detection understanding what are the patterns, what are the behaviors that we're seeing that associated with threats. And then we have to take a decision. Are we going to block the threat? Are we going to just live with it?
Are we going to just let it play on? Is it really something that we that is important? Is it something that we need to generate a response? And then when we generate a response, what should that response be?
Are we gonna shut down the workload? Are we going to, maybe just counter that particular action by an attacker So again, a lot of decision making that needs to take place and unlike with scanning where we have a little bit of time usually to to to, defend the risk those decisions and the responses really have to happen fast because if a and and and tech is underway and people are starting to siphon data off of your environment, we need to shut that down as soon as possible. Right? We can't wait, you know, a week or two like like we would maybe fixing a vulnerability.
So A little bit more data, right, Apple is also providing that active protection to to our customers. And we are monitoring, a lot of workloads in the in the environment. So we are seeing on average, again, from our data, about a hundred and thirty six types of threat activity. So that would be the method attackers are using. So a hundred and thirty six unique methods that we've seen that attackers are using to, either probe the environment or gain a foothold in the environment or execute the threats in the environment. We are seeing, and this is the data that is about, a month old.
During the course of a month, these are not, you know, real time running, workloads, but over the course of a month because workloads come and go, there is an aggregate, thirty five thousand four hundred workloads with threat activity per month. So so think about it. Right? They are at least those amounts of of of workloads that could be affected by an attack, and we need to sort and make the decision really quickly on whether or not we want to respond to an This is even worse because we have, you know, hundreds of thousands of threat activities per day. Right? So On average, if you think about it, there are about, you know, four, five, six threat activities per day per workload.
And that means that we are starting to see a lot of inflow into our security information management systems and to the decision making of whether or not we want to to identify the thread. And those require us to really be vigilant. Right? We need to understand exactly what's going on in the container what's going on in a function and exactly what's going on in your VM and and understand whether or not this is part of a threat, part of an attack and make that that that that respond as as quick as possible.
And to be honest, it's just a lot to deal with. Security organizations, are not really built to do this the way that we used to do it with, servers. Right? Because the amount of workloads is increasing the amount of complexity, putting workloads in a cloud environment is is complex, and everything that we talked about in the previous session. Again, if you haven't heard that, go go and listen to it and we'll describe the the, that complexity and why the volume of both findings and attacks have been have been increasing.
So it's a lot to deal with. Now it doesn't mean that we just need to give up. It just means that we need to work a little bit smarter. But before we work smarter, let's let's just describe how we work today in general on both sides.
Right? The scanning for risks and and and doing threat detection in real time. Well, right now, for the most part, even in cloud native, this is still a siloed process. These are still two distinct processes that happen in environments.
On the one side, we scan for risk and, you know, identify them prioritize and fix them to the best of our ability. And we're using objective measures. Right? In order to understand if the risk should be prioritized, we are using things like, the scores like, the severity of the, of the vulnerability or the the the misconfiguration, we are able to, then based on those objective measures, prioritize how we want to, fix those and then, you know, measure that we indeed fixed them.
Now we're not gonna fix everything just because of the volume. But those objective measures are thought to be enough to actually prioritize, our threats. A similar thing is happening in runtime. Runtime doesn't have as much as methodology of scoring that it has on the on the risk side, but there are some frameworks like the minor attack framework that that if you can map our detections of what is going on behaviorally inside of an application, we can actually understand, you know, what decision we need to take because we know what phase of the attack this is associated with and and whether or not we have a, an attack in in place once we see an aggregate of those of those threats.
And again, this is a completely different, different function, and sometimes it's handled in a different part of the the organization.
It means that, the people that scan for risks and scan for, let's say, cloud misconfigurations are doing their and in parallel, other people probably the security operation center, probably with the help of security information management, are looking at those threats and determining whether or not they need to generate a response.
This is a problem. It's a problem because those two organizations are still drowning in a lot of findings.
And and the fact is that sometimes we find ourselves covering and prioritizing risks that maybe would not lead to a threat being exploited, right, because the that Venn diagram between risk and threat is not a hundred percent match. On the other hand, we could find ourselves chasing a lot of threats that look like they can be exploited, but because of the structure of the infrastructure and because of of, maybe some compensating measures, really attackers won't be able to execute their attacks. So there's a lot of time and effort wasted in both these silos and things that are not relevant.
And again, because we're drowning in a lot of data, it could be the one that we are missing. It could be the one that we are not prioritizing, and then the attack, might have So we really need a better way. And this is where we start to to put these two things together. If we could have a synergy between what we do with scans and what we do with runtime.
If we can feed data from one to the other, we should be able to have a better outcome actually on both sides.
So if we take everything that we know about the risk ins and the result of the risk ins, so we know what risks are in the wild, and it's not just the objective measure of the vulnerability severity and score. It's also whether or not there is active vulnerabilities exploit that happens in the wild. Do we have an exploit published, which makes it a lower barrier to entry for attacks to exploit it? That should actually hone what we do at runtime and we can, have better decision making as we do the response.
Same thing with the component source. Right? If we're seeing components that are being active at runtime, but their source is questionable whether or not they're coming from the external externally to the organization or they have, maybe the repos are not well maintained and there is a chance that, there may be some repo pois poisoning Again, we can hone our policies, we can hone our response on the threat side. And another very important thing that comes with scans is really the expected behavior because it's not just the objective measure of what the risk is and, whether or not we have vulnerabilities or misconfigurations, it also speaks to what the components of the application and what we we expect the applications to do.
Right? We have the ability to see, let's say, in Docker files, the the entry point of the of the the container in Kubernetes files. We have the expected, ports that are going to be used in what's being exposed. So so we can actually start to see what the expected behavior again, which will help us hone our decision response at runtime.
Sending actually happens the other way around.
What we're able to do is to take the data that we have at run time and reflect on what we actually need scan or better yet what we need to prioritize in order to fix the threat. Right? So if we have, you know, a hundred thousand vulnerabilities in, let's say, across thirty thousand resources, But we know from our runtime detection that really only, you know, five thousand, six thousand upload resources are are in use, that those are the ones that we need to prioritize on the scan because those are the ones that any intrusion is going to happen. Right?
Intusion is not going to happen on a code that's not running. Same thing happens with the existing mitigation. There is a vulnerability that could cause a remote code execution. It's dependent on a porch being open or it's dependent on the ability of the user to gain shell access.
And we block those two things. You know, we don't allow shell access or we don't allow, traffic on a particular port, then again, maybe we need to deprioritize that. On the other hand, if there are vulnerabilities that we are seeing that we that we know that we don't any existing mitigation at runtime.
Then first of all, we can put up that that that mitigation at runtime if we can, but also those are the ones that we need to prioritize.
In order to fix. And of course, they're just the general observed behavior. Right? We need to statistically understand, what where the threats first steps are coming from, whether the things that, attack as we're trying to exploit and not in a general sense, that's not the temporal score of what's out there in the wild.
This is actually what's happening in each and every environment so that you can have better understanding of the risks that are being exploited. And again, we can prioritize them, to make that a much more ironclad environment so that we don't have that risk to begin with. That attackers will not be able to to exploit it. So all of these things are leading us to needing a lot of data.
And what are the things if you've seen our last session is that Akwa's research arm, we we call team Nautilus are the ones that are responsible to provide us with the data both objectively and eventually leading to the data based on our environment as to what the risks are and what the threats are. Now we have components that sit all the way in the development environment in the code repos, in the CICD, we can scan images from the registry, scan artifacts as they are running and provide the that runtime detection.
At, for threats that happening when, when workloads are actually up. So all of that is, a result all the recent. I'll I'll give you two examples. Right? If if we are talking about just the risk and let's take vulnerabilities for instance, we all know that vulnerabilities have a severity and they have a score.
And there are multiple ways to do that scoring, you know, the c b s s one and c b s two and c b s three. And we are now finding ourselves in a way that we need to classify that that that vulnerability. Well, it's not just two or three or four data points. They are actually, you know, dozens of data points that we can look at at a particular vulnerability it could be, you know, where the vulnerability is coming from, what image in your environment is it coming from?
What is the severity of that unability. What is the authoritative score? It could come from the NVD as an objective score, or it could come from the maintainer of the package. If it's an open source package, and sometimes they disagree, and we need to understand that if we are going to prioritize that correctly.
We need to understand if there is a an exploit code exists. If right now, things are being exported in the world. We need to understand, you know, where are the containers that are running, what the workloads they are running, what resources are there, how to fix them, how to fix them in a way that, might just update that component, or do we need to update the entire, let's say, base operating system? So these are all data points that we can use in order to make a decision on whether or not we want to prioritize a particular vulnerability in our environment.
Now, you know, multiply that by hundreds of thousands, and and we do get, a lot of, a lot of data, but it's data that actually is not hurting us. It's not an overwhelming amount of data. It's just data that helps us prioritize and and aquaize an automated system can can really help you prioritize based on all the the data points.
Another thing is on the risk side, on the, on the threat side. Right? What's happening on the threat side is, again, a lot of behaviors that are taking place inside of our, workloads. Some of them are benign. Some of them are are more dangerous than others. Some of them are only dangerous in combination.
So we have over a hundred types of threat activity. Right. Remember, we are finding a hundred and thirty six on average.
Individual, threat patterns that we identify in in our customers. We are mapping those to the minor categories so you can get some objective measures about what's going on in the environment. But then we also want to reflect specifically on cloud native. You know, are we going against Kubernetes?
Are we going against the container engine. Are we trying to, preempt what was in the image and insert more executables into a container. So this is this is the list of of, typical actions that would happen in real time. And we are we are also sorting them and we're able to to provide, that analysis, of an individual action that happens whether or not it is in a process of an active attack, or is it just something that is detached and just happened once?
And of course, in cloud native, because everything is replicated, we can also reflect on whether or not it happens in a lot of workloads or in some workloads and and there's no, you know, good good or bad of whether or not an attack is less important because it happens in work with one workflow or multiple workloads. We just need to take it as a data point and add that to the decision of the of the response. So by taking all these data points together and and all the different workload types that we have in cloud native, what we are able to do is to, have a continuous assessment, of risk leading into an assessment threat.
So, you know, on the risk side, we can, you know, scan our VMs to understand if there are misconfigurations or or vulnerabilities. We can do that, of course, with the cloud.
We can, scan containers, based on the images that they have, come from. We can take a look at the Kubernetes resources, take a look at the Kubernetes configuration files a lot of times we wanna put an acceptance gate so that if we are seeing a workload that is gonna come with something that is a risk. We might want to deny that risk and prevent that risk from going into runtime.
In containerizations specifically because we are always dependent on the image. We have the ability to identify drift between a running container and its image. That's usually an indication that something is going wrong, not an indication necessarily of an active attack, but a very strong data point, that we we can plus it's it's always a good idea to stop changes to running, cloud native workloads because they're supposed to be immutable. And then we have, the ability to put some runtime policies in place that would harden it rushing to lock attack in in action, and provide you with, with at least a little bit of time to understand what goes on so that you are able to fixed fixed the risk or or have more of an elaborate incident response.
Of course malware is part of it and just general threat detection pattern based to to understand what goes on. Now the middle part there, you know, where it says cloud native only, these are really specific to cloud native, but we don't have the ability to you know, do containers if we're just running in VMs. We also don't have Kubernetes if we're if we're just running in traditional VMs. But we also don't have this acceptance Right? Because VMs are built over time and are not just triggered from a prefab image. So all these qualities of what cloud native is, and again, for to our previous session, are are going to both, you know, increase the complexity of of what we need to defend, but also gives us a little bit of help because it provides us with a baseline on which we can we can base our our responses.
So when all of this is put together, the ideal is that if we identify an attack and if we can correlate that to a risk that is already known, we will have much more confidence on how we can stop that attack. And this is where we are, gonna show you in our next session, that is gonna be next week around how can we affect an effective response without downtime in those cloud native applications? Well, how can we, detect that risk make sure that at risk is appropriate for our environment.
And then if we see a threat that tries to exploit that risk, how can we stop it without taking down the application with us. There's a lot of interesting things that Apple is doing at runtime in order to prevent those cloud native attacks from from, coming on, but also stop them, when they're there. So, I hope you'll join our next session when we discuss how we can actually bring all this together. And stop cloud native attacks without impacting the application.
Thank you so much.
See, folks, I put a link into, into the chat. Lot of reference of last week's session. For those who didn't make it, there's a link to the recording right in the chat. You can, check that out, at your leisure, and then also a link to the registration page for next week.
So, Tsvi, thank you so much. That was a lot of great information.
Watch Next