
Tracee is powered by eBPF technology. eBPF enables users to run programs that help with the observability of the system. In this blog post I will discuss what eBPF is, why you would use it, and to what end. I will also walk you through an example of how I implemented eBPF to trace system calls.
You can learn more about Tracee in this blog post published by Liz Rice.
Now, let’s take a deep dive into eBPF and learn what the technology is used for.
What is eBPF?
eBPF stands for Extended Berkeley Packet Filter. The full version of the acronym doesn’t do much justice to the actual abilities of the technology. In Brendan Gregg’s own words: “eBPF does to Linux what JavaScript does to HTML.” I encourage you to check out his work on eBPF and tracing in general.
eBPF stems from the original idea of BPF, which was to capture useful network packets directly from the kernel, without copying them to user space and then funneling them out through a network tap.
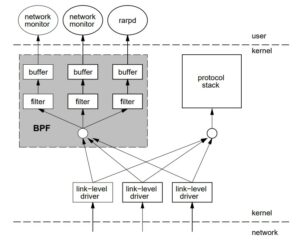
BPF filters out unnecessary traffic and retrieves only those packets that are monitored, thus reducing the overhead of copying unnecessary packets into user space, and then later sieving through them.
BPF runs code in the kernel in order to decide which packets to filter in or out. eBPF greatly extends this capability to more than packet filtering, enabling you to run arbitrary eBPF code in the kernel. Your eBPF programs can be triggered by many different types of event, not just the arrival of network packets. For example, you can trigger eBPF code to run when a kernel function starts by attaching the program to a kprobe event. Because it runs in the kernel, eBPF code is extremely high performance.
In the early days, it was necessary to manually write an eBPF program in bytecode. This was an error prone and tedious process. Fortunately, you can use toolkits such as BCC (BPF Compiler Collection), to write eBPF programs in modern day languages like Go and Python. More on this later in this blog.
Why Do We Need to Use eBPF?
Because eBPF programs can be triggered by a whole range of events, eBPF-based applications such as Tracee help you discover what is happening in your system. You can say that there are existing tools that do just that, for example, `ps`. However, the catch is timing resolution. Programs that have a shorter execution runtime than the sampling interval of your monitoring tool will not be detected. Because eBPF code is event triggered, rather than sampling-based, and because it runs blazingly fast in the kernel, eBPF-based observability tools are much more accurate than traditional sampling-based alternatives.
An example of eBPF’s strengths is workload monitoring–by identifying applications’ anomalous behavior, such as writing files into important system directories. eBPF code can run in response to file events to check if those are expected for that workload.

What Can We Do with eBPF?
For the purposes of this blog post, I wrote a sample program that demonstrates the capabilities of eBPF by tracing execve() system calls.
The execve() system call is triggered when a program attempts to execute a program read from a file. The eBPF program I wrote monitors all the processes that call execve() and reports on them. We will be able to see every new executable that is run on the system since we executed our program.
Monitoring execve() system calls is useful to detect unexpected executables. For example, suppose we observe an execve() call spawning a shell from within a container. Containers are usually short-lived enclosures of a microservice, and spawning an interactive shell is not typically what a container would do. This can be an indication that an attacker is trying to take over our system.
Enough Talk–Show Me the Code!
A BPF program consists of two parts: the kernel space and user space program. The kernel space program is responsible for capturing relevant events and making them available to user space. The user space program takes the events generated by the kernel space program and parses them for further use.
In this example we will first look at the kernel space code, how it runs inside the kernel, and sends events to the user space. Next, we will look at the user space code, how it is able to parse the received events.
In order to help development, the community has come up with frameworks such as BCC. We can register a callback with the BCC framework for capturing all execve syscalls such as the following:
int syscall__execve(struct pt_regs *ctx,const char __user *filename,const char __user *const __user *__argv,const char __user *const __user *__envp) |
The following function will capture running commands using the BCC call:
bpf_get_current_comm(&data.comm, sizeof(data.comm)); |
And will put the event details, such as the command name, return code, parent UID, and process UID into a perf ring buffer that the user space program can read from:
BPF_PERF_OUTPUT(events); |
Similarly, for the user space code, I will use the Golang bindings for BCC. Let’s jump into Go and set up our BCC program:
type Snoopy struct {m *bpf.Module}func main() {s := Snoopy{m: bpf.NewModule(source, []string{}),}defer s.m.Close()if err := s.LoadAndAttachProbes(); err != nil {log.Fatalf("failed to load and attach probes: %s", err)}} |
In this code snippet, we’re creating a new struct and instantiating the bpf module inside. We pass the source parameter which holds the BPF code that will run in the kernel. Then, we call the LoadAndAttachProbes() function. Let’s learn a bit about probes:
Probe
- A probe is an extension point defined by the kernel where a BPF program can be attached.
- Probes are designed to collect and transmit information about the subsystem they are attached to.
- There are various kinds of probes available within BPF. The ones we’ll use here are
kprobeandkretprobe.
Let’s learn what they mean and what they can do:
kprobe
syscall__execvekretprobe
A kretprobe is a special prefix for a probe that is responsible for tracing of a kernel function return. So, in our case it will be do_ret_sys_execve
Let’s take a look into how we attach and instrument the kernel with our new BPF program, by taking a look at the LoadAndAttachProbes() function.
func (s Snoopy) LoadAndAttachProbes() error {fnName := bpf.GetSyscallFnName("execve")kprobe, err := s.m.LoadKprobe("syscall__execve")if err != nil {log.Printf("failed to load syscall__execve: %s", err)return err}if err := s.m.AttachKprobe(fnName, kprobe, -1); err != nil {log.Printf("failed to attach syscall__execve: %s", err)return err}kretprobe, err := s.m.LoadKprobe("do_ret_sys_execve")if err != nil {log.Printf("failed to load do_ret_sys_execve: %s", err)return err}if err := s.m.AttachKretprobe(fnName, kretprobe, -1); err != nil {log.Printf("failed to attach do_ret_sys_execve: %s", err)return err}return nil |
It can seem a bit complex at first, but all that the above code snippet is doing is loading and attaching the kprobe and kretprobe to our BPF program. After being successfully loaded, we can proceed by running the rest of the program.
table := bpf.NewTable(s.m.TableId("events"), s.m)
|
Before we go further, we must understand what tables means in the context of running a BPF program.
BPF programs communicate between user space and kernel space using maps. Maps are generic key value data structures that are used to store data. For example, a Hash Table is a BPF Map.
In our case, we instantiate a BPF map of type Hash Table and call it events. We also pass in a data channel where all our events will be received. To read them we run an event loop in a goroutine as follows:
func (s Snoopy) eventLoop() {for {data := <-s.dataChannelvar event execveEventerr := binary.Read(bytes.NewBuffer(data), bpf.GetHostByteOrder(), &event)if err != nil {log.Printf("failed to decode received data: %s", err)breakComm: C.GoString((*C.char)(unsafe.Pointer(&event.Comm))),Pid: event.Pid,Ppid: strconv.FormatUint(event.Ppid, 10),RetVal: event.RetVal,}out.printLine(p)}} |
Here we can see that we’re reading from the dataChannel we created earlier and doing a binary.Read() operation of the incoming bytes on the stream. We further unmarshal the byte buffer into an eventPayload and print it out on stdout. Now let’s run this program and see what happens.
Note: you must run BPF programs with superuser privileges.
# go run main.go
As previously described, we will monitor each shell that is spawned inside a container. Let’s spin up a nginx container in the background:
$ docker run -d nginx
Let’s run a sh shell from within the bash shell as follows:
$ docker exec -it 9e02dfdeb94f /bin/bash$ sh |
The output of our BPF program each new process:
TIME(s) PCOMM PID PPID RET ARGS5.908 docker 8854 3154 0 /usr/bin/docker exec -it 9e02dfdeb94f /bin/bash6.214 bash 8886 8875 0 /bin/bash8.779 sh 8919 8886 0 /bin/sh |
You might notice that the Parent Process ID (PPID in short) for the sh shell matches the Process ID (PID) for the bash command, but the bash command’s PPID doesn’t match the PID of the docker command. That is because the docker command makes a request to the Docker daemon, which in turns launches the shell inside the container.
Conclusions
As we see from the above example, eBPF programs are an extremely powerful basis for system monitoring software. With a few lines of code, you can instrument your system and keep track of what’s happening inside.
The downside of an eBPF-based approach for security tooling is that you can only observe new processes or file access events, as they start-– you cannot prevent them from starting. These observations can tell you when a workload behaves in an unexpected way, and you could use that to trigger actions, perhaps to shut the process or the container down. However, if this unexpected behavior was a malicious action, the damage may have already been done.
This lack of prevention capabilities is an unavoidable shortcoming of eBPF-based security tooling. In contrast, the Aqua Cloud Native Security Platform makes use of powerful proprietary technology, which can not only notify you when unexpected behaviors occur but can also prevent them from happening in the first place.
